
OpenShift Pool Release: Avoid These Common Mistakes for a Smooth Deployment
OpenShift, Red Hat’s Kubernetes distribution, provides a robust platform for containerized application development and deployment. A critical aspect of managing OpenShift is releasing and managing node pools. Proper node pool management ensures optimal resource allocation, performance, and scalability. However, even experienced administrators can stumble. This article will delve into common pitfalls associated with OpenShift pool releases and provide actionable advice to help you avoid them, ensuring a smooth and successful deployment.
Understanding the Importance of Node Pool Management
Node pools are essentially groups of worker nodes within your OpenShift cluster. These nodes host the pods (your applications). Efficient node pool management directly impacts:
- Resource utilization: Avoid wasted resources and ensure applications have the capacity they need.
- Application performance: Properly sized and configured node pools contribute to faster application response times.
- Scalability: Effectively scaling your applications relies on the ability to add or remove nodes from your pools.
- Cost optimization: By avoiding over-provisioning, you can minimize infrastructure costs.
- Availability: Well-managed node pools contribute to cluster health and high availability.
Common Mistakes to Avoid During OpenShift Pool Releases
Let’s explore the key areas where mistakes often occur during OpenShift node pool releases and how to mitigate them.
1. Ignoring Resource Requirements and Pod Placement
One of the most frequent errors is failing to properly consider the resource requirements of your applications and how they will be placed on the nodes.
- Underestimating resource needs: Deploying applications with insufficient CPU, memory, or storage requests can lead to performance bottlenecks and application failures.
- Ignoring node affinity and tolerations: Failing to use node affinity, anti-affinity, and tolerations can result in pods being scheduled on the wrong nodes, potentially impacting performance or violating security requirements.
- Lack of monitoring and alerting: Without proper monitoring, you won’t know when your node pools are reaching capacity, leading to unplanned outages.
Solution:
- Thoroughly analyze application resource needs: Profile your applications to understand their CPU, memory, and storage demands.
- Define resource requests and limits: Configure resource requests and limits for your pods to ensure they have the resources they need and don’t consume excessive resources.
- Utilize node affinity and tolerations: Use these features to control pod placement, ensuring applications are scheduled on the appropriate nodes based on hardware, software, or other criteria.
- Implement comprehensive monitoring and alerting: Monitor resource utilization (CPU, memory, storage) at the node and pod levels. Set up alerts to notify you of potential issues.
2. Improper Node Sizing and Configuration
Choosing the wrong size or configuration for your nodes can have significant consequences.
- Incorrect node size: Selecting nodes that are too small leads to resource exhaustion, while nodes that are too large waste resources.
- Inadequate storage configuration: Failing to configure sufficient storage or the correct storage class can hinder application performance and data persistence.
- Ignoring node labels and taints: Node labels and taints are essential for organizing and managing your nodes, and a lack of attention to them can complicate management and deployment.
- Not using autoscaling: Failing to enable the Cluster Autoscaler can lead to manual scaling and potential downtime.
Solution:
- Right-size your nodes: Base node size selection on the resource requirements of your applications and the expected workload. Consider using different node sizes for different workloads (e.g., compute-intensive vs. memory-intensive).
- Configure storage appropriately: Select the correct storage class and provision sufficient storage capacity based on application needs. Consider performance, reliability, and cost when choosing storage options.
- Utilize node labels and taints: Use labels to categorize nodes (e.g., “region,” “environment,” “application”). Use taints to prevent pods from being scheduled on specific nodes unless they have matching tolerations.
- Enable and configure the Cluster Autoscaler: Ensure your node pools can automatically scale up and down based on demand.
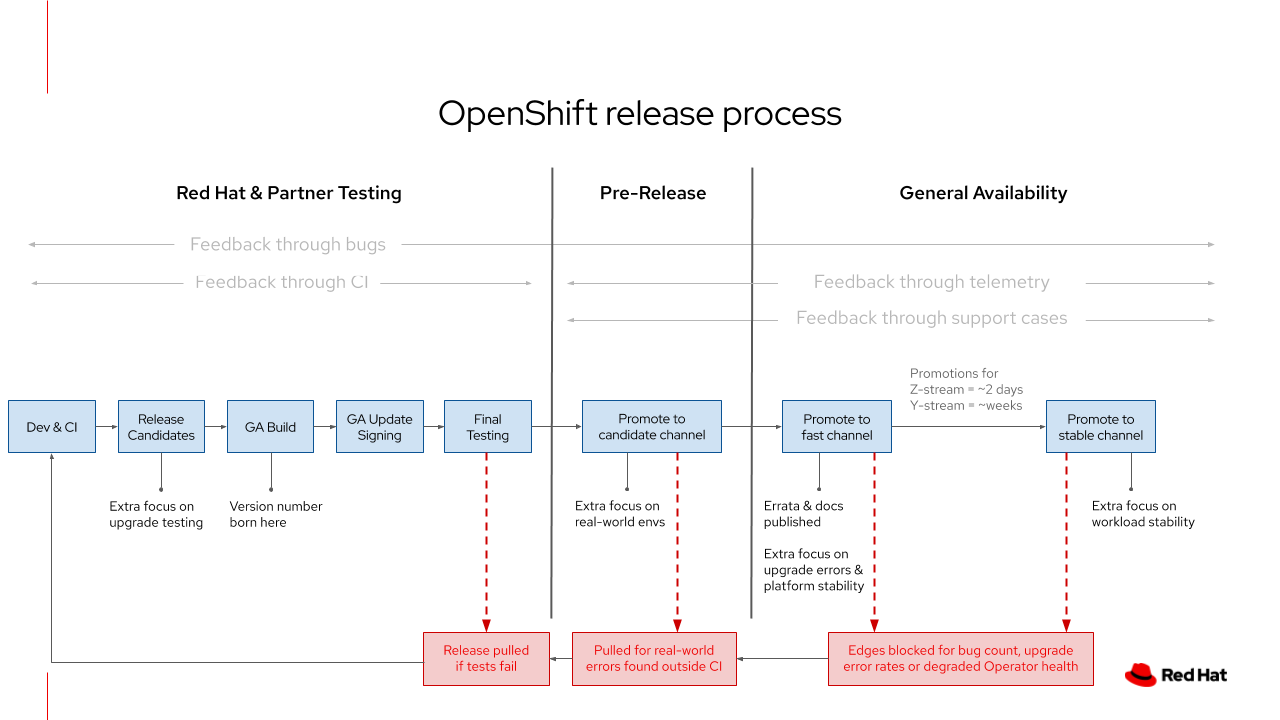
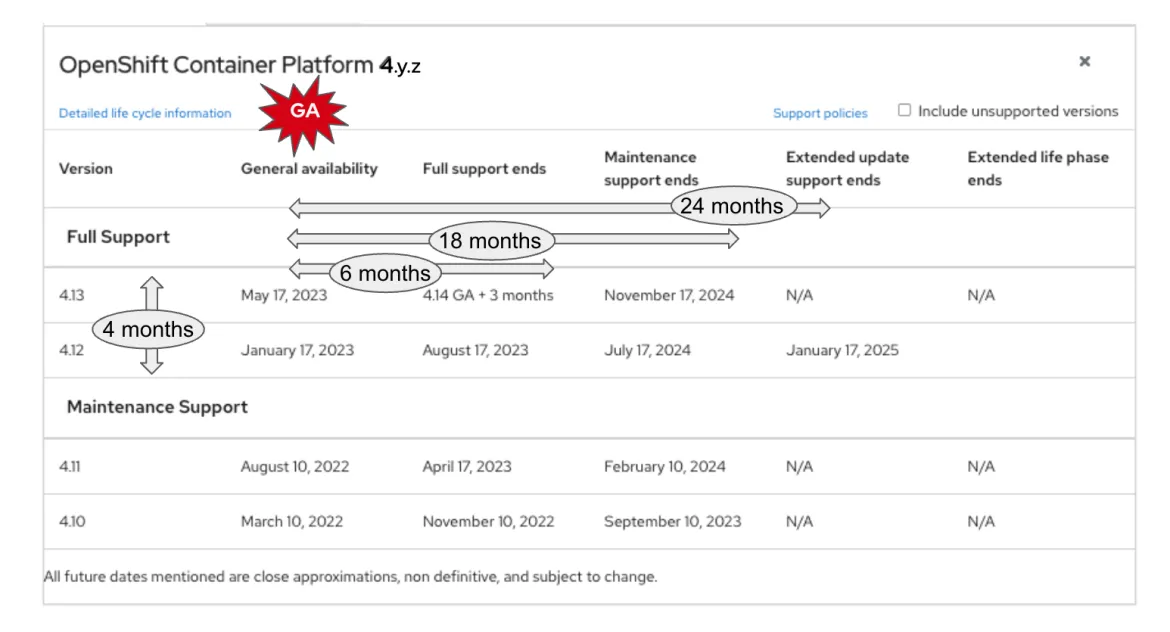
3. Neglecting Update Strategies and Rollbacks
Rolling out updates to node pools is critical, but a poorly planned strategy can lead to downtime.
- Lack of a well-defined update strategy: Without a plan, updates can disrupt running applications.
- Insufficient testing before deployment: Failing to test updates in a staging environment can result in unexpected issues in production.
- Inability to rollback: Without a rollback plan, you may be stuck with a broken deployment.
- Ignoring the impact on running applications: Node pool updates can impact running applications. Consider using strategies like rolling updates with pod disruption budgets.
Solution:
- Develop a robust update strategy: Choose an update strategy that minimizes downtime, such as rolling updates or blue/green deployments.
- Test updates in a staging environment: Thoroughly test updates in a staging environment that mirrors your production environment before deploying them to production.
- Implement a rollback plan: Have a plan to quickly revert to the previous configuration if an update fails.
- Use pod disruption budgets (PDBs): Define PDBs to control the number of pods that can be unavailable during an update, ensuring application availability.
- Monitor the update process: Closely monitor the update process and be prepared to intervene if any issues arise.
4. Security Vulnerabilities and Misconfigurations
Security is paramount, and neglecting it can expose your cluster to risks.
- Insufficient security hardening: Failing to secure nodes and applications can create vulnerabilities.
- Using default configurations: Default configurations often have security vulnerabilities that must be addressed.
- Lack of network segmentation: Not properly segmenting your network can allow unauthorized access to sensitive data.
- Ignoring patching and updates: Failing to regularly patch and update your nodes can leave them vulnerable to exploits.
Solution:
- Implement security best practices: Follow security best practices for OpenShift and Kubernetes, including hardening your nodes and applications.
- Customize configurations: Review and customize default configurations to enhance security.
- Implement network segmentation: Use network policies to segment your network and control traffic flow.
- Regularly patch and update: Keep your OpenShift cluster and all its components up-to-date with the latest security patches and updates.
- Implement Role-Based Access Control (RBAC): Configure RBAC to control user access and permissions within the cluster.
5. Ignoring Monitoring and Logging
Without proper monitoring and logging, you are flying blind.
- Lack of monitoring: Without monitoring, you won’t be aware of performance issues, resource constraints, or other problems.
- Inadequate logging: Without proper logging, it will be difficult to troubleshoot issues and identify the root cause of problems.
- Not setting alerts: Failing to set up alerts for critical events will mean you are not proactively notified of potential issues.
Solution:
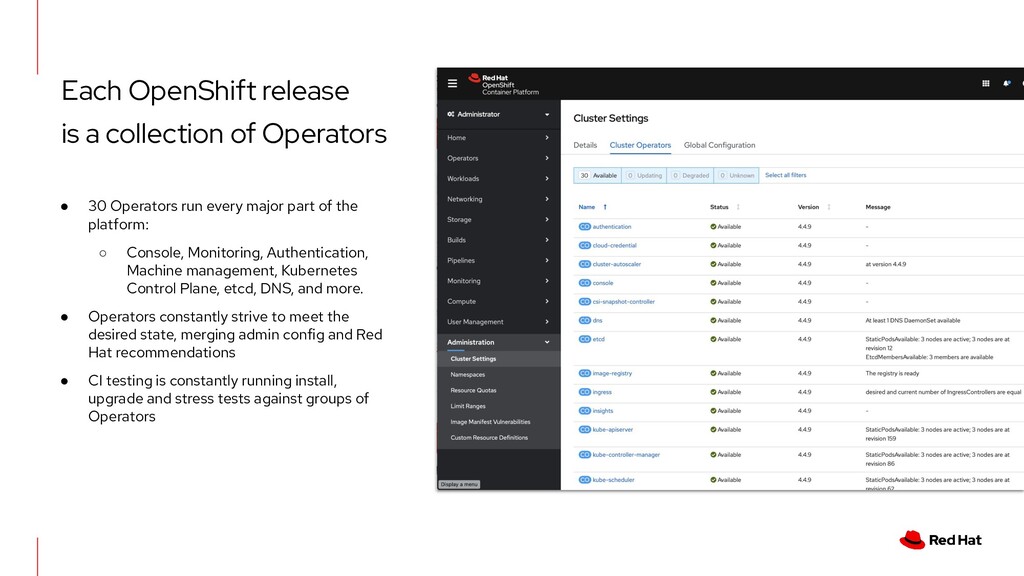
- Implement comprehensive monitoring: Monitor all key metrics, including CPU, memory, storage, network, and application health.
- Set up centralized logging: Collect and store logs from all components of your OpenShift cluster in a centralized location.
- Configure alerts: Set up alerts to notify you of critical events, such as high resource utilization, application errors, or security breaches.
Conclusion: Achieving OpenShift Pool Release Success
Avoiding these common mistakes is crucial for ensuring the smooth and successful release and management of your OpenShift node pools. By paying careful attention to resource requirements, node sizing, update strategies, security, and monitoring, you can build a robust and reliable OpenShift environment. Remember to continuously monitor your cluster, adapt to changing needs, and learn from your experiences to optimize your deployments. This proactive approach will lead to improved application performance, reduced downtime, and a more efficient and cost-effective OpenShift infrastructure.
Frequently Asked Questions (FAQs)
1. What is the difference between a node and a node pool in OpenShift?
A node is a single physical or virtual machine that hosts your applications’ pods. A node pool is a group of nodes that share the same configuration and are managed together. You can have multiple node pools in an OpenShift cluster, allowing you to segregate workloads based on different requirements.
2. How do I choose the right node size for my OpenShift node pool?
The optimal node size depends on the resource demands of your applications. Consider the CPU, memory, storage, and network requirements of your workloads. Start with an estimate and monitor resource utilization. Adjust node sizes based on observed performance and resource consumption. Consider using different node sizes for different workloads.
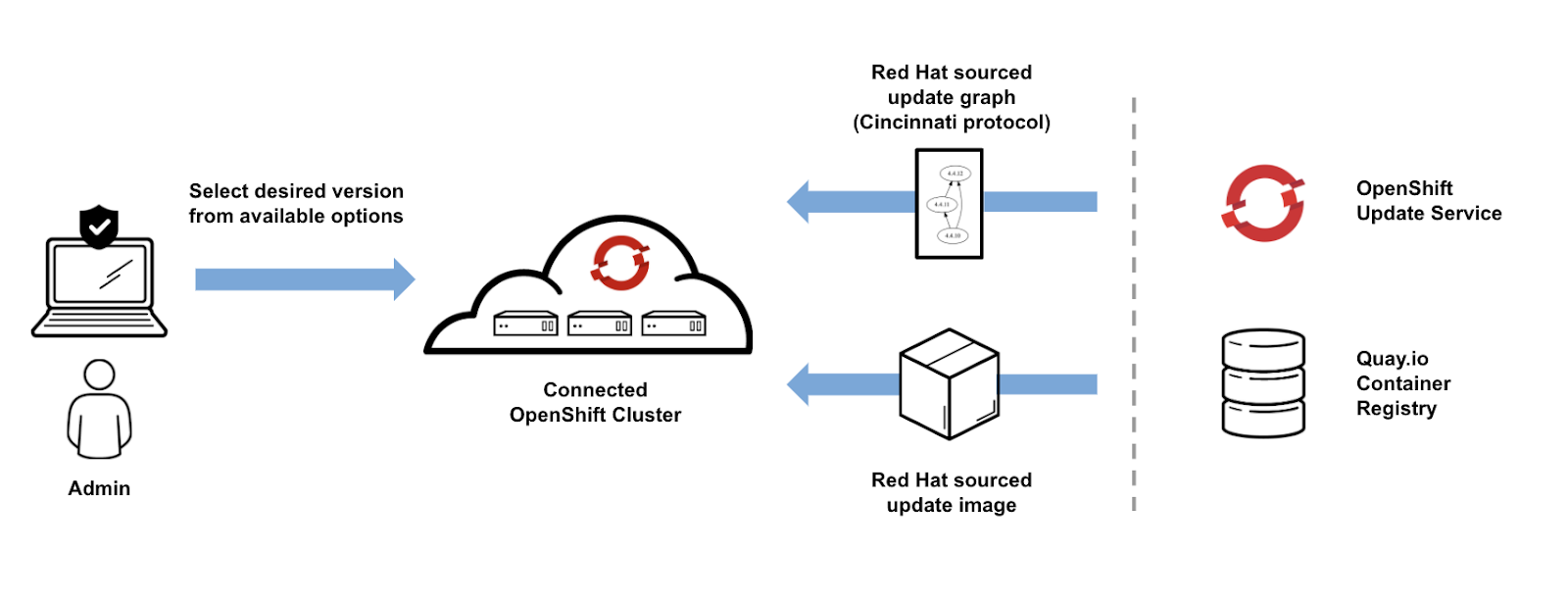
3. What are rolling updates and how do they help with node pool releases?
Rolling updates are a deployment strategy where new pods are gradually rolled out while the old pods are gracefully terminated. This ensures application availability during the update process. OpenShift’s built-in rolling update mechanism helps to minimize downtime by updating nodes one at a time or in batches, ensuring continuous service.
4. How can I monitor my OpenShift node pools effectively?
Use a comprehensive monitoring solution that tracks key metrics like CPU utilization, memory usage, disk I/O, network traffic, and application health. Set up alerts to notify you of potential issues, such as high resource utilization or application errors. Use tools like Prometheus and Grafana, which integrate well with OpenShift, to visualize and analyze your metrics.
5. What is a Pod Disruption Budget (PDB) and why is it important?
A Pod Disruption Budget (PDB) specifies the maximum number of pods from a replicated application that can be unavailable during voluntary disruptions, such as node updates. PDBs help to ensure application availability during rolling updates or other maintenance operations. They prevent too many pods from being unavailable simultaneously, minimizing the impact on your application’s users.
